Information about PEKI dictionary
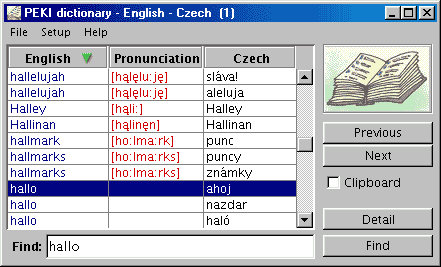
This explanation is based on a English-Czech dictionary database.
- The program allows to find some informations from a translation
dictionary database (e.g. English-Czech) - in a graphical
user interface (GUI).
- Program allows to create (and to use) more independent dictionary
databases.
- Program can translate an expression from the first language to second one
as well as to back. Column items are sorted by a corresponding language rule.
- It is allowed to sort and to find a record by phonetic transcript of
Pronunciation.
- Each record is separated into four parts (same parts can be empty of course) in the style:
- English (English expression)
- Pronunciation (phonetic transcript of pronunciation)
- Czech (Czech explanation)
- Detail description (a space for grammar, synonym, etc.)
- Program has got implemented support for a quick search mode: the result
is finding continuously just like the user is writing a character by character.
User can disable this feature on a slow computer.
- Program saves your status for new running (quick search status,
look and feel, the last used database etc.).
- The PEKI dictionary is language independent. It is allowed to create
more binary databases with different languages and code
pages. A user can switch a database in the runtime (in finding
mode). There is possible, the current document isn't translated into all supported languages.
- The latest version of the program, some history changes and more informations
you can found on PEKI dictionary homepage peki.wz.cz.
CONTENT:
There is possible to run PEKI dictionary program on some operating system
type of Windows, Linux, MacOS, OS/2, Solaris and more, which have got installed a
Java Runtime Environment (JRE) type of "all languages, including English"
version 1.4 or newer. The JRE can be free downloaded from:
More informations about an installation are described in document
read-me.htm.
If you have got a first running, then you will can verify some parameters for creating a binary
database(s) in a special form. A more informations are described in special
chapter Data Import.
- Select a column according to your language request by a mouse click on
header of column.
The selected column will be highlight by a green arrow
 . Than you can write a wanted expression
in a text filed labelled Find.
The text verify by Enter key,
or by a mouse click on Find button.
. Than you can write a wanted expression
in a text filed labelled Find.
The text verify by Enter key,
or by a mouse click on Find button.
- You can leaf through result list by a hot keys
PgDn, PgUp,
Arrow Up and Down.
- Show a detail by a button
Detail, complementary hotkeys
are Enter or Alt-Enter.
This is highlighted a selected attribute by a green arrow
 on the end of text.
on the end of text.
- If the detail content is too long, you can use some hotkeys for navigation in the space.
Use Ctrl-End for skipping to end of detail, Ctrl-PgDn
for moving to next page or Ctrl-ArrowDn for moving to next row.
- If you want to show current document, choice Help item from menu:
Help.
- Select a check box Text
from clipboard if you want (automatically) to translate
a text copied into system clipboard.
- You can change a translation of graphical user interface (like buttons, menu and labels)
between a next languages:
 - English
- English - German
- German - Russian
- Russian - Ukrainian
- Ukrainian - Czech
- Czech
You can change a current language from menu
Setup,
but the change can't have a influence on the current document.
- You can close the application from menu:
File ->
Exit.
I am recommending to use a characters from next table for description of pronunciation.
Attribute Hexa contains a hexadecimal number
of a character set called Unicode.
| Byte |
Hexa |
Description |
Sample |
| ą |
0105 |
width "e" |
apple |
| ę |
0119 |
voiceless vowel |
around |
| ń |
0144 |
nasal consonant |
bank |
| đ |
0111 |
voiced phone "th" |
they |
| 0 |
0030 |
voiceless phone "th" |
width |
The application is freeware, it means that
you can use it for private and commercial purpose without any charges.
It is forbidden to decompile the application or to anywise modify.
The author is not responsible for any damages related with using the application.
A vocabulary source has got his own licence and an enclosed
pronunciation has got his own licence too.
If the program does not find some database, then the one shows to user a form
for specification of data source for creating a new database.
You may to write at least a name of text dictionary source file, the
column languages and code page of data source.
An each row of data source will be a one row in the database.
The row have got a next data format:
<English><TAB><Pronunciation><TAB><Czech><TAB><Detail-1><TAB>...<Detail-N><LF>
There is an explanation of expressions in the next table:
| <English> |
The English expression.
The item is formatted by CSS style c1 in a detail mode. |
| <Pronunciation> |
There is recommended to enclose a pronunciation into square brackets [...] .
If the all pronunciations will be empty,
the table column Pronunciation will be hidden.
The item is formatted by CSS style c2 in a detail mode. |
| <Czech> |
A Czech translation.
If the all items will be empty,
the table column will be hidden.
The item is formatted by CSS style c3 in a detail mode.
|
| <Detail-?> |
The expression can contains practically unlimited count of detailed description
items. The length of one item is
practically unlimited too.
The text can contains a tags of HTML language.
The items are not mandatory.
The item is formatted by CSS style c3 in a detail mode.
|
| <TAB> |
Tabulator is intended for a separating of text items.
There is possible to change a separator to any kind of character string - in form for
data import. |
| <LF> |
Character Line Feed is intended for new record set of dictionary.
The application recognizes a new line declared by
<CR><LF> too (a Windows convention). |
A header of source text file can contain a comment.
There are respected all rows starting by character # like header comment.
The comment is finished by the first row, which does not begins with this
character. The comment you can see in an information window
About database ...
opened from menu of the application.
Remarks:
- Select a combo box Source doesn't contain pronunciation
if source file does not contains a Pronunciation item.
- Select a combo box No empty explanation
if you want to ignore a not translated rows - in time database creation.
- You can change a look of detail view by CSS style definition. You can assign the CSS file
before creating a binary database, then the CSS style will be a part of binary database.
If you does not specify CSS style, then an internal CSS settings is used.
The binary database contains all information required for runtime of PEKI program.
- The application respect a nationally sorting of columns by locale of current
column, but no by selected language of user interface (labels).
- Database constrains: the maximal size of binary database can be 2048 MB (exactly 2.147.483.647 bytes).
Know, the large database will have a bigger request on RAM
memory in a index creating time. You can to copy a binary database created on powerful computer into weak
computer.
- You can to affect the result size of binary database (and related speed of
finding) by the right selection of internal code page of columns.
There is a common rule the 256 characters code page save (usually) data more
economically than a UNICODE supported code page.
 |
A basic name of the application -
PEKI is compounded from some characters of my son forenames -
Petr
Kamil.
He was born in the same year as the first version of this program was
created :-). |
The document was written 2004/10/30 by author: Pavel Ponec, pponec@seznam.cz
Translation: Pavel Ponec